Naver News Comment Analysis (3)
TL;DR
어뷰저는 존재한다. 하지만 그들을 완전히 통제하고 제거하는 것은 불가능하다. 그렇다면 어뷰저를 막는 것에 집중하지 말고, 어뷰징은 내버려두되 그 효과를 랭킹 시스템을 바꾸어 완화시키는 방법은 어떨까?
네이버 뉴스 플랫폼에서는 순공감과 공감비율을 통해 공감이 많은 의견을 상위에 랭크시키고 있다. 각각의 알고리즘이 가진 결함도 문제지만, 과연 정치적 의견의 장에서 공감이 많은 의견만이 우리가 듣고 보아야 할 의견일까? 특히나 어뷰징이 있는 상황에서 공감수가 많은 의견은 더욱 획일화된 주장을 펼칠 수 밖에 없으며 대중은 편향된 의견만 접하게 되어 무의식적으로 다양한 사고에 대한 가능성을 차단받는다.
그래서 이번 글에서는 다양한 의견이 상위에 랭크될 수 있는 sorting algorithm들을 제안한다. reddit과 yelp 등에서 사용하고 있는 알고리즘을 비롯하여, 논쟁적인 댓글이 상위에 위치할 수 있는 알고리즘, 그리고 비공감이 많은 댓글에 더 높은 점수를 부여하는 알고리즘 3가지를 소개한다.
Introduction
모두가 다 알고 있는 사실이지만, 어뷰저는 존재한다. 드루킹과
에서 나온 결론으로도 뒷받침될 수 있지만 트위터에
m.news.naver.com/comment 라고 검색하기만 해도 아래와 같이
댓글 조작의 흔적을 쉽게 발견할 수 있다.
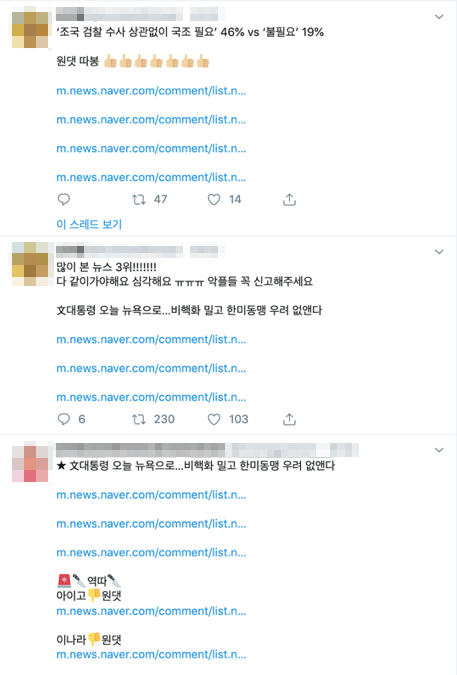
이렇듯 쉽게 어뷰저의 존재를 찾을 수 있음에도 네이버가 어뷰저를 잡지 않는 이유는 그 일이 생각처럼 쉬운 일이 아니기 때문이다.
n초 안에 여러번 공감과 비공감을 지속적으로 받은 댓글은 어뷰징의 결과로 의심한다. 그 댓글을 지워야 할까? 만약 댓글을 쓴 유저가 어뷰저가 아니었다면 문제가 될 수 있다.
사후 분석을 통해 어뷰저로 의심되는 댓글의 내용을 지우는 방법은 어떨까? 뉴스라는 매체의 특성 상 시간이 지난 기사는 사람들이 관심있게 보지 않는다. 그러므로 이 방법은 어뷰저를 막는다고 볼 수 없다.
분석을 통해 어뷰저라고 강하게 의심되는 유저를 차단한다고 하더라도 새로운 패턴으로 어뷰징을 하는 유저들이 생겨날 것이다. 어뷰저의 기준을 세우는 것은 어려운 반면 새로운 방식으로 어뷰징을 하는 것은 좀 더 쉽기 때문에 이렇게 물고 물리는 싸움은 어뷰저에게 유리하다.
그렇다면 어뷰저를 차단하는 것에만 집중하지 말고, 어뷰징은 내버려두되 그 효과를 완화시키는 방법은 어떨까? 지금 네이버 뉴스 댓글 랭킹 방식은 그것이 미치는 영향력에 비해 너무 간단하고 단편적이다. 구글의 검색 랭킹이 신뢰도를 가지고 있는 이유는 상위에 랭크된 글이 '조작'을 통해 만들어지지 않았다는 점 때문일 것이다. 그 이유는 정보가 되는 글에 대한 정보량, 품질 기준이 보다 엄격하고 단편적인 면으로만 순위를 매기지 않기 때문이다. 만약 구글 랭킹이 웹문서의 클릭수로만 되어 있었다면 어땠을까? 많은 기업들이 본인의 홈페이지를 상위에 랭크시키기 위해 많은 조작이 일어났을 것이다.
그래서 이번 글에서는 그렇게 간단하다고는 볼 수 없는 다른 랭킹 algorithm에 대해 소개해보려고 한다. 현재 네이버 뉴스 댓글 랭킹 방식 중 순공감순, 공감비율순, 답글순의 한계점을 살펴보고 reddit과 yelp에서 신뢰도있게 쓰이는 best 랭킹과 새로운 관점의 controversial 랭킹 algorithm을 소개한다.
Naver News Comment Sorting System
Sorting Algorithms
2019년 9월 기준, 총 5개의 정렬방으로 서비스되고 있다. 드루킹 논란 이후 댓글 제공 여부와 정렬방식을 언론사가 선택하는 방식으로 바뀌었다.
- 순공감순: 공감 - 비공감[1]
- 공감비율순: 공감 / (공감 + 비공감)
- 답글순
- 최신순
- 과거순
이 중, 댓글에 대한 사용자의 인터랙션(공감, 비공감, 답글)으로 순위를 매기는 순공감순, 공감비율순, 답글순에 대한 문제점을 하나씩 짚어보고자 한다.
Limitations
순공감순
순공감순은 우리의 직관과 벗어나는 랭킹이라는 점에서 한계가 있다. 우리는 절대적인 공감 수치보다, 공감비율로 댓글의 신뢰도를 평가한다.
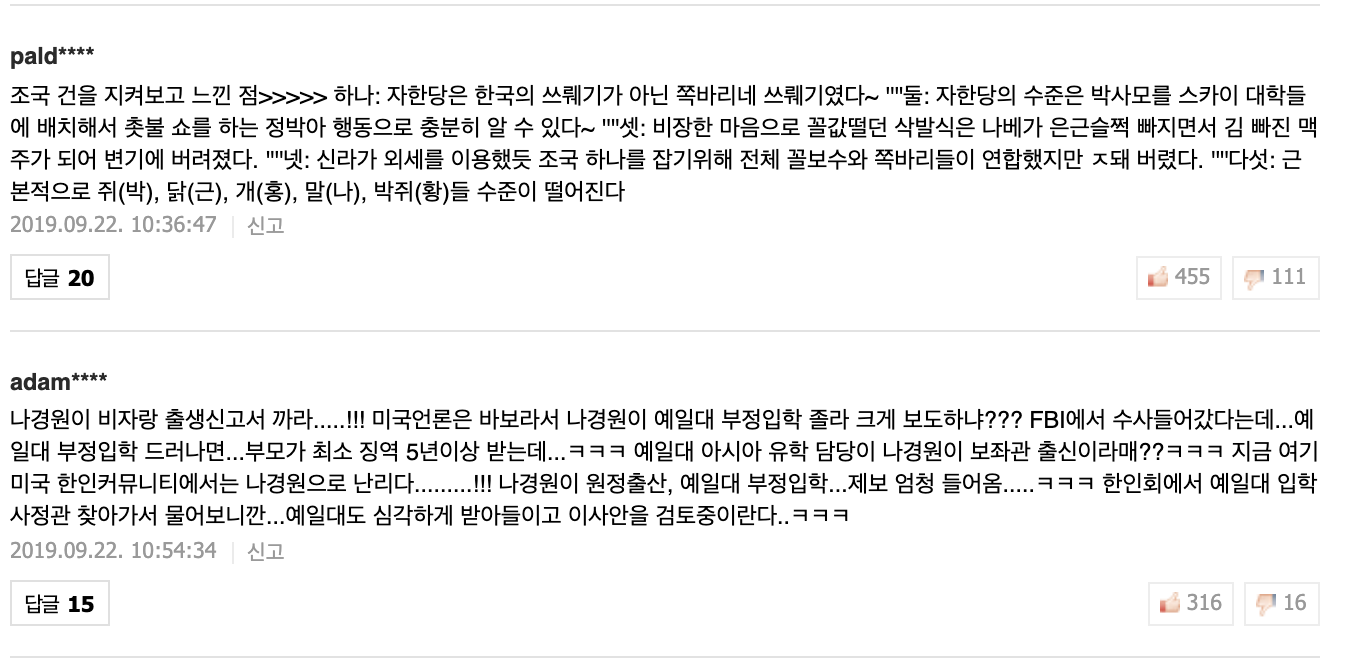
아래의 사례는 네이버 뉴스 댓글[2]의 실제 예시이다. 첫번째 댓글은 순공감 344개(= 455 - 111) 로, 300개(= 316 - 16)의 순공감을 지니는 두번째 댓글보다 더 높은 순위에 자리한다. 하지만 각각의 댓글의 공감비율은 80.4%(= 455 / (455 + 11)) 로, 두번째 댓글의 공감비율인 95.2% (= 316 / (316 + 16)) 보다 작다.
공감비율순
앞서 설명한 것처럼 공감비율순이 좀 더 우리의 직관과 유사한 척도이다. 하지만 공감비율순은 전체 공감, 비공감 수가 적을 때 문제가 된다.
소수의 사람들에게만 노출된 댓글은 공감과 비공감의 개수가 모두 적어 100% 라는 공감비율이 쉽게 만들어지는 반면, 여러 명에게 노출된 댓글은 하나의 비공감만 달리더라도 그보다 낮은 공감비율을 지니게 되는 문제가 발생한다.
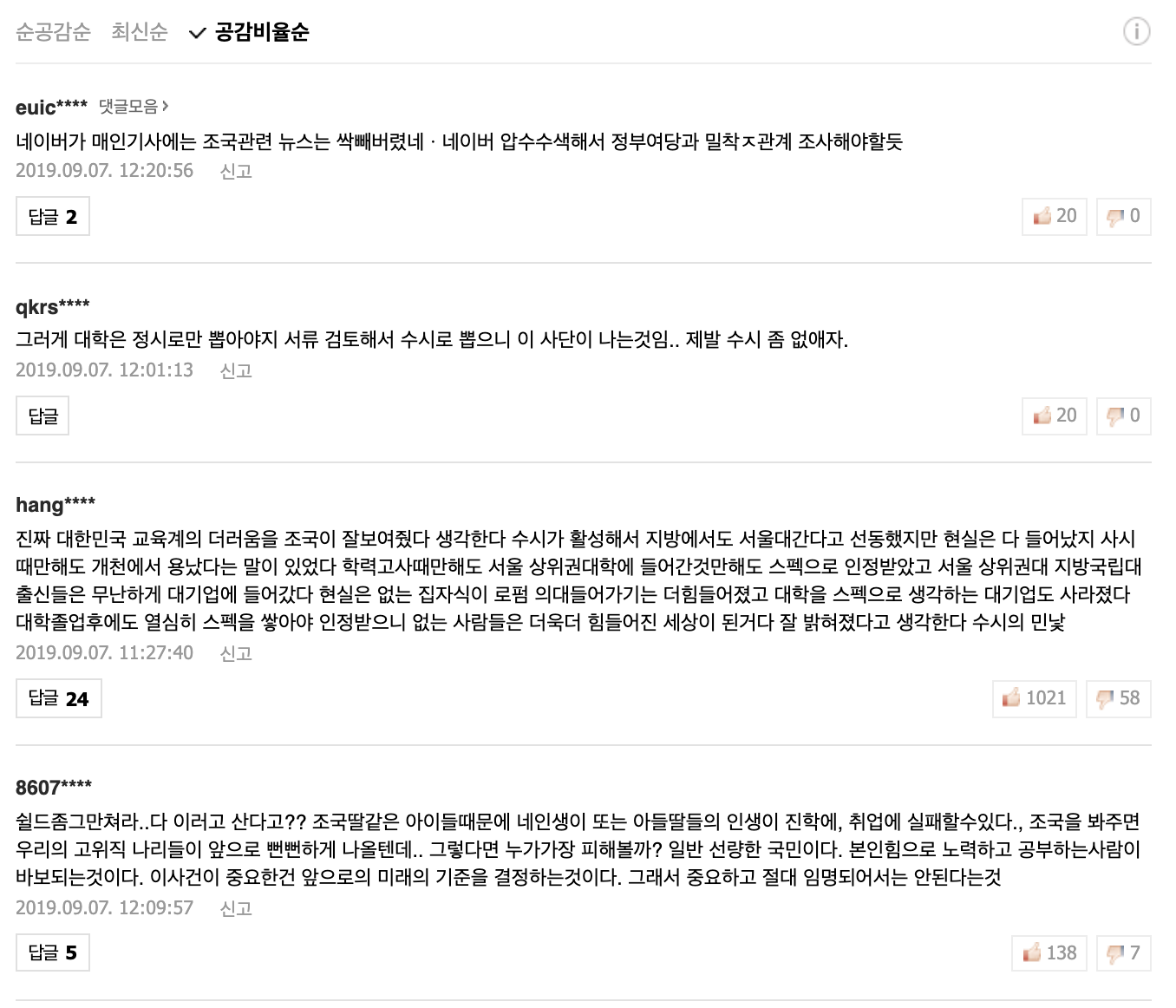
아래의 네이버 뉴스 댓글 예시[3]에서 공감수가 20, 비공감수가 0인 댓글이 비공감을 전혀 받지 않아 공감비율 100%가 되어 더 많은 사람들이 읽고 공감을 표한 공감수 1021, 비공감수 58인 댓글보다 더 상단에 위치한다.
답글순
여러 개의 답글이 달리는 댓글은 주로 일찍 남겨진 댓글 중에 인신공격이나 뉴스 외 주제에 대한 댓글인 경우가 많다. 댓글 공간에서는 명확한 내용으로 구성된 댓글에 대해서는 대댓글 보다도 공감 혹은 비공감으로 본인의 주장을 표시하는 것이 일반적이다. 그러나 감정적으로 쓰여진 댓글은 그 댓글에 자극을 받은 다른 사용자의 답글로 이어지고 되므로 답글 개수를 기준으로 댓글을 정렬하면 뉴스 내용과는 무관한 자극적인 댓글들이 우선적으로 노출된다.
또한 일찍 쓰여진 댓글일수록 더 많은 사람들에게 노출될 가능성이 있으므로 대부분 뉴스 작성 시점과 가까운 댓글이 상위에 랭크된다.
랭킹 algorithm으로 보기에는 정렬 기준이 controllable하지 않으며 댓글의 유익한 속성이 높게 평가되어 정렬되는 랭킹이라고 볼 수 없다.
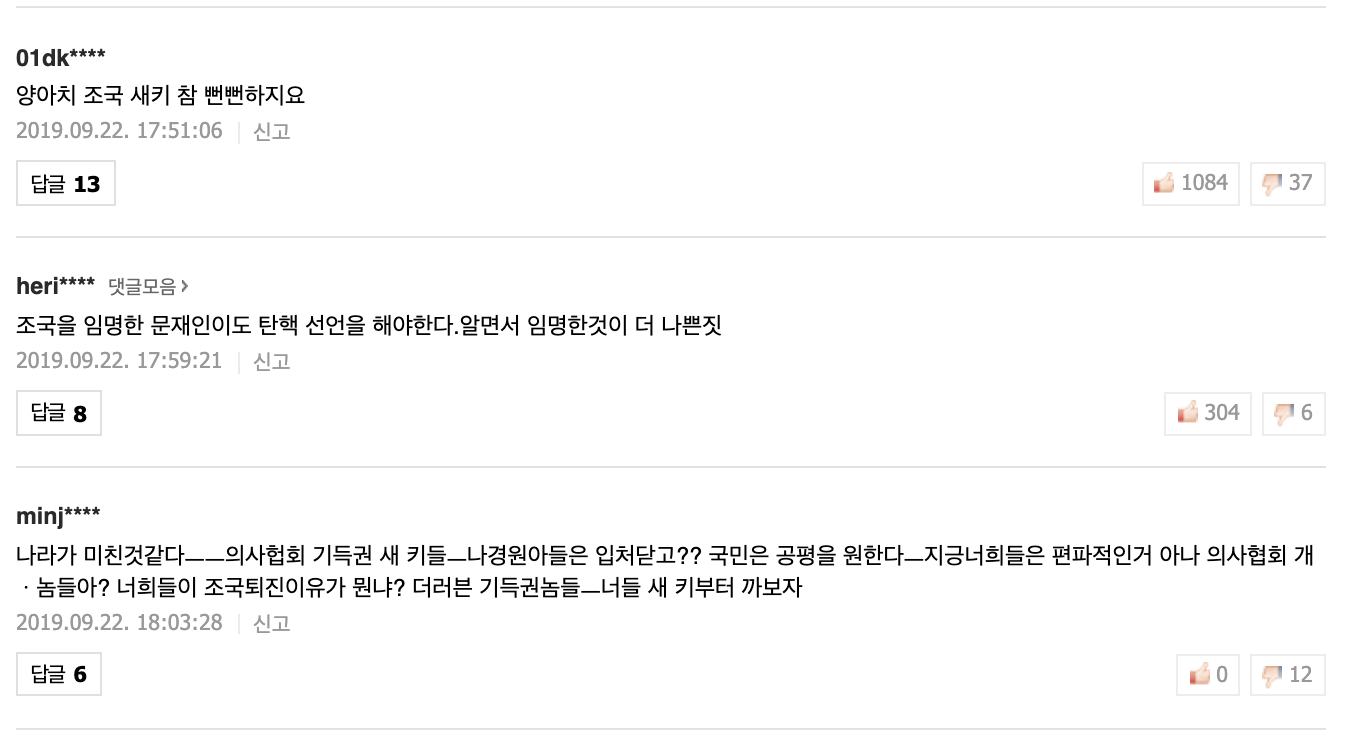
아래의 네이버 뉴스 댓글 예시[4]를 보면 vote 수가 많지 않아도, 공감수가 전혀 없고 비공감만 받더라도 top 10에 위치할 수 있다.
Reddit Comment Sorting Algorithms
댓글이 활발하게 생성되는 플랫폼은 비단 네이버 뉴스 뿐만은 아니다. 네이버 쇼핑, 네이버 호텔, 망고 플레이트, reddit, stackoverflow, yelp, amazon 등의 다양한 플랫폼에서 수집되며 플랫폼에서는 다시 이 데이터를 가공하여 사용자에게 유익한 정보를 제공한다.
그 중에서도 reddit의 랭킹 시스템이 앞서 비판했던 순공감순, 공감비율순의 한계를 극복한 sorting algorithm을 제공하고 있기에 자세히 살펴보려고 한다. reddit의 랭킹 방식에는 best, top, new, controversial, old, q&a가 있다. top이 순공감순, new가 최신순, old가 과거순이다.

Best
Best ranking[5][6] 은 Wilson score[7]로 정렬한 것으로, 공감비율순의 단점으로 언급되었던, 전체 vote수가 적은 상황을 smoothing시켜준 algorithm이다. reddit뿐 아니라 yelp에서도 사용한다고 한다[8].
Wilson score는 주어진 positive와 negative vote가 binomial distribution을 따른다고 가정했을 때, positive 발생 확률을 95% 신뢰구간의 최소값으로 추정한 값이다.
동전 뒤집기 상황에서 앞면을 positive, 뒷면을 negative라고 하자. n번 던진 후 앞면이 나올 확률(\(p\))을 추정할 때 n이 충분히 큰 경우 central limit theorem에 의해 \(p\)는 normal distribution을 따른다. 따라서 95%의 신뢰도로 \(p\)를 추정하여 \(p\)의 최소값, 최대값을 구할 수 있고 이 때 최소값이 Wilson score가 된다. 자세한 수식은 Appendix A에 정리해두었다.
\[ w^- = max(0, \frac{2n\hat{p} + z^2 - z\sqrt{z^2 + 4n\hat{p}(1-\hat{p})}}{2(n+z^2)})=\text{wilson score} \]
위의 식을 함수로 구현하면 다음과 같다.
import numpy as np |
아래의 예시는 네이버 뉴스 댓글에 Best ranking algorithm을 적용해본 결과이다. 공감비율순 정렬이었다면 "원칙대로만 하시면 됩니다 역사에 부끄럽지 않게 잘 해 주세요"는 1000개 이상의 vote를 가진 "법대로 해라 법은 만인 앞에 평등하다"는 댓글을 제치고 상위에 랭크되었을 것이다. 하지만 Best 정렬방식에서는 vote 수가 적은 경우 약간의 penalty를 받기 때문에 하위에 랭크되었다.
- MB '정치보복' 반발에 문무일 총장 "법적 절차대로 하겠다"[9]
| comments | 공감수 | 비공감수 | best score | 공감비율 |
|---|---|---|---|---|
| 법대로 해라 법은 만인 앞에 평등하다 | 1091 | 55 | 0.938 | 0.952006980803 |
| 법대로 하면 사형인데 !! | 562 | 39 | 0.936 | 0.935108153078 |
| 제발 법대로만 해주세요. 그래도 나라를 지옥으로 만든 죄는 물을 법도 없다. 이 악마야!!! | 252 | 14 | 0.933 | 0.947368421053 |
| 지금까지 반발하고 나서 살아남은 넘을 못봤다. | 565 | 38 | 0.933 | 0.936981757877 |
| 혓바닥몇번 낼름거릴까나했더니 찔렸나보네ㅎㅎ | 595 | 37 | 0.932 | 0.941455696203 |
| 본인이 구린짓을 했으니까 먼저 발광하는거겠지.. | 686 | 43 | 0.931 | 0.941015089163 |
| 법대로 하는 것보다 더 정의로운 절차는 세상에 없다 | 4146 | 317 | 0.926 | 0.928971543805 |
| 당연히 법대로 하셔야죠 | 296 | 14 | 0.921 | 0.954838709677 |
| 원칙대로만 하시면 됩니다 역사에 부끄럽지 않게 잘 해 주세요 | 302 | 13 | 0.921 | 0.95873015873 |
| 법대로 합시다 | 919 | 51 | 0.92 | 0.947422680412 |
기본적으로 공감수가 많은 댓글을 상위에 랭크시키는 알고리즘이기 때문에 어뷰징 작업으로 공감수가 부풀려진 댓글이 top 10 밖으로 밀려나지는 못한다. 하지만 vote수가 적더라도 경향성을 파악해 댓글을 정렬시키기 때문에 단순한 순공감이나 공감비율순으로는 하위권에 있던 댓글이 상위권에 위치할 기회를 증가시켰다.
어뷰저 입장에서는 쉽게 계산할 수 있는 정렬방식이 아니기 때문에 조작이 어려워질 것이다. 어뷰징을 할 때 고의로 공감과 비공감을 섞어서 해당 댓글을 상위에 랭크시키는데, Best 정렬이라면 "적당"한 비율을 맞추기 까다로워질 것이다.
Controversial
controversial[10]은 이름 그대로, 공감과 비공감이 팽팽하게 맞서는 댓글을 상위에 위치시키려는 알고리즘이다. 단순히 팽팽하기만 하면 공감과 비공감이 1:1인 상황과 10:10인 상황이 같다고 생각할 수 있기에 vote수도 sorting algorithm에 포함시켜서 10:10이 1:1인 상황보다 더 controversial할 수 있도록 만들어졌다.
아래의 식에서 upvote는 공감을, downvote는 비공감을 의미한다. upvote와 downvote의 차이가 같아서 분모가 같아진 경우에는 그 크기가 큰 쪽이 높고, vote의 크기가 같은 경우에는 차이가 작은 쪽이 높다.
\[ \text{controversial} = \frac{match \times log(match + 1)}{| upvote - downvote | + 1},\text{ where }match=min(upvote, downvote) \]
python으로 구현한 식이다.
import math |
좀 더 직관적인 이해를 돕기 위해 가공한 아래의 예시를 보자.
| upvote | downvote | controversial score |
|---|---|---|
| 1001 | 1000 | 3454.38 |
| 999 | 1000 | 3450.42 |
| 100 | 100 | 461.52 |
| 101 | 100 | 230.76 |
| 1000 | 700 | 15.24 |
| 130 | 100 | 14.89 |
| 100 | 130 | 14.89 |
| 1 | 1 | 0.69 |
| 1 | 2 | 0.35 |
upvote, downvote의 비율이 비슷한 댓글 순서로 정렬되고, 그 비율 내에서는 vote 수가 큰 댓글이 더 위에 놓이게 된다.
controversial algorithm을 네이버 뉴스 댓글에 적용해보았다. 예상대로 공감과 비공감 수치가 비슷하면서도 vote수가 많은 댓글이 가장 먼저 보인다. vote수가 작은 이유는 이미 순공감 노출로 인해 vote를 받을 기회를 박탈당한 댓글들이기 때문이다.
수치와는 무관하게 top 10 댓글의 내용은 얼마나 controversial하게 구성되어 있는지 정성적으로 평가해보았다. 보도자료에 대한 찬성은 푸른색, 반대는 붉은색 , 애매한 문장은 표기하지 않았다. controversial하다면 뉴스 기사의 주제에 대해 찬성과 반대가 골고루 섞여있어야 할 것이다.
- 아베 "한미군사훈련 예정대로"…文대통령 "내정문제 거론 곤란"(종합)[11]
| userId | comments | 공감수 | 비공감수 |
|---|---|---|---|
| user 1 | 대통령 각하, ‘사드 문제’ 갖고 거품무는 중국에도 내정 간섭이라고 거침 없이 말씀해주세요 | 26 | 26 |
| user 2 | 이제는 한미일군사훈련을 해야 한다. | 81 | 85 |
| user 3 | 근데 왜 중국한테는 대놓고 내정간섭 받는거죠, 대통령님? 치욕스러웠던 조선시대가 그리운건가요? | 22 | 22 |
| user 4 | 봐라 ㅋㅋㅋ 연기하지?철수 얘기나온다 백퍼 ㅋㅋㅋㅋ 베트남꼴 나는거야 ㅋㅋㅋ 정신 좀 차리자 | 33 | 31 |
| user 5 | 아베만도못한 문통; | 11 | 11 |
| user 6 | 문재인 아가라 닥쳐라. 사드도 내정문제인데 중국한테는 끽소리 못 하던 색히가 어디서 주둥아리 씨부리노. | 10 | 10 |
| user 7 | ㅋㅋㅋㅋㅋㅋ 곧 양념단와서 또 평화올림픽 울부짖겠네. | 66 | 57 |
| user 8 | 미국이 한국을 버려야 할 듯.없네. | 15 | 14 |
| user 9 | 미국을 대변하는거다.국익을 최우선으로 하는거지싫지만 아베가 똑똑하지않는냐.살자. | 8 | 8 |
| user 10 | 얼마나 답답하면 저런말을 할지 생각 안해보셨나요?? 북에서 원하는 대로 흘러가네요. 앞으로 한미군사훈련 연기뿐만 아니라 축소되고 없어지고 난리나겠네 | 8 | 8 |
분명 공감수와 비공감수는 controversial하지만 대부분이 당시의 여론과 반대대는 내용으로 치우쳐있다. 정성적으로 controversial한 댓글은 공감: 비공감이 1:1이 아닌 좀더 공감 비율이 높은 비율을 가진다는 사실을 유추해볼 수 있다.
공감비율과 비슷하게 controversial도 vote수가 많은 경우에 불리해진다. controversial의 분모는 upvote와 downvote의 차이값인데, vote수가 많을수록 한두개차이를 유지하기가 어려워진다. 공감 66, 비공감 57을 가진 댓글이 공감 10, 비공감 10보다 아래에 놓인다.
New Sorting Algorithms
reddit ranking algorithm 중에서 controversial의 문제점을 해결한 새로운 controversial algorithm과 비공감이 많은 의견도 노출하는 best anti 정렬방식을 제안하고자 한다.
New controversial
앞서 지적했듯이 controversial은 공감: 비공감의 비율 재조정과 vote 수가 많은 경우 분모값의 기준을 완화시켜야하는 이슈가 있다.
공감 : 비공감 정성적으로 확인해보았을 때 공감: 비공감 = 6.5 : 3.5 정도에서 기사 내용에 대한 찬성과 반대의 댓글이 골고루 등장하였다. 때문에 new controversial에서 upvote와 downvote의 값을 조정해주어야 한다.
vote수가 많은 경우 이 문제는 공감비율순과 비슷했다. upvote와 downvote의 절대치에 의존하기보다 wilson score로 도출된 값을 upvote와 downvote로 대체하면 vote수가 많고 적음을 고려하면서도 0과 1 사이의 값을 가지게 되어 upvote와 downvote의 차이에 대한 효과가 완화된다.
변경된 내용을 정리하면 다음과 같다.
import math |
- 아베 "한미군사훈련 예정대로"…文대통령 "내정문제 거론 곤란"(종합) [11]
| userId | comments | 공감수 | 비공감수 |
|---|---|---|---|
| user 11 | 아베한테 대하듯 똑같이 김정은하고 북한, 중국한테도 당당하게 나와라! | 16 | 11 |
| user 12 | 개~~새끼 아베 한테는 그렇게 당당하면서 김정은한테는 왜 그렇게 꼬리를 내린다냐? 핵이 무섭긴 무서운가 보다 | 11 | 7 |
| user 13 | 한미 동맹도 좋다 그러나 우리 나라 스스로 강한 나라가 되어야 한다. 문대통형 수고 많으십니다 !! | 9 | 6 |
| user 14 | 아베에게 일침을 놔주신문 대통령님 지지 합니다.나대지 마시오 | 9 | 6 |
| user 15 | 쪽바리 추종자들 많네!! 특히 벌레 틀딱들~~ | 8 | 5 |
| user 16 | 반대로 우리나라가 일본보고 자위대 훈련하는거 보고 참견하면 일본이 가많이 있겠냐?벌레들아! 비판을 하려면 국내 내정에 간섭하는 아베를 비판해야지 아베를 두둔하냐? 이 스레기들아... | 8 | 5 |
| user 17 | 아베가 옳은말했네 지금이라고 김정은 참수 한미연합훈련을 시작하라 빨갱이한테 이 나라를 줄 수 없다 | 6 | 4 |
| user 18 | 대한민국은 다시 한번 망해봐야 정신차리지..안된다. | 6 | 4 |
| user 19 | 일본이 우방이란애들 멍청한거 아니냐 일본애들도 그렇게 생각안하는데 왜 니혼자 망상해 찐따새끼인가ㅋㅋㅋㅋㅋㅋ | 6 | 4 |
| user 20 | 문재인씨 당신의 국적은 어디입니까? 다스 실소유주를 밝히는 것보다 훨씬 더 중요한 문제입니다. | 6 | 4 |
공감 비율을 조금 높여주었을 때 기사 내용에 찬성하는 댓글과 반대하는 댓글이 top 10에 골고루 섞이게 되었다. 또 wilson score로 변환한 상태에서 비율을 조정해주게되어 vote수가 높은 경우에 up과 down의 차이에 덜 민감해질 수 있었다.
Best-Anti
꼭 공감수가 많은 것만 괜찮은 의견이라고 볼 수 있을까? 비공감수가 많은 의견 또한 반대 진영의 입장을 대변하는 좋은 의견이라고도 볼 수 있지 않을까?
네이버 뉴스 댓글은 대부분 당시의 여론에 따라 분위기가 흘러간다. 순공감순이든 공감비율순이든 한가지 주장을 다른 방식으로 표현하고 있는 댓글들이 top 10이 된다. 이를 보는 대중은 한쪽의 영향만 받게 되어 생각이 더욱 치우쳐진다.
정치적 다양성을 수용하는 것은 의견의 객관성을 유지하는데에 도움이 된다. 그런 의미에서 당시 여론과 반대되는 내용의 댓글 또한 보여주는 것은 댓글에 영향을 받을 다른 사용자를 위해서도, 플랫폼의 중립성을 담보하기 위해서도 중요하다고 생각한다.
Best-Anti는 negative vote에 대한 Wilson score를 구한 것이다.
\[ w_{neg}^- = max(0, \frac{2n(1-\hat{p}) + z^2 - z\sqrt{z^2 + 4n\hat{p}(1-\hat{p})}}{2(n+z^2)}) \]
python 구현식은 다음과 같다. import numpy as np
def best_anti(up, down):
try:
z = 1.96 # 95% confidence level
n = up + down
p_up = up / n
p_down = 1 - p_up
denominator = 2 * (n + z**2)
numerator = 2 * n * p_down + z**2 - z * np.sqrt(z**2 + 4 * n * p_up * p_down)
lower = numerator / denominator
except ZeroDivisionError as e:
lower = 0
return max(0, lower)
- 아베 "한미군사훈련 예정대로"…文대통령 "내정문제 거론 곤란"(종합)[11]
| userId | comments | 공감수 | 비공감수 |
|---|---|---|---|
| user 21 | 평화협정후 미군철수 바랍니다 | 0 | 5 |
| user 22 | 홍발정씨..트럼프도 좌파 빨갱이죠?? | 0 | 4 |
| user 23 | 늙다리 미치광이는 빠져 줄래!자주통일좀 하자! | 0 | 4 |
| user 24 | 자국당은 사형감 많던데... 미국철수 애기했다고 파면? 자국당 5월에는 문정인으로 놀고먹겠군~! | 0 | 4 |
| user 25 | 봐라. 지도자 하나가 이렇게나 세상을 바꿀 수 있다. 물론 촛불 들고, 직접민주주의를 구현한 국민 또한 위대하지. 지방선거 때 투표 잘 하자. | 0 | 4 |
| user 26 | 아직도. 미국이 인계철선이라믿고 50년대 사고방식이 존재하는구나 군사력 세계10위안에들고 1-1붙어도 안지니 너무 미군철수로 여론전말고 참신한거없어요 ? 자한당분들? | 1 | 6 |
| user 27 | 극우 자한당은 미국도 빨갱이란다 제비가 왔다고 봄은 아니람서 ㅋㅋㅋ | 0 | 3 |
| user 28 | 원샷-빅딜! | 0 | 3 |
| user 29 | 자한당분들께서 트럼프도 좌파래요.. | 0 | 3 |
| user 30 | 잊지마세요 지금도 북한은 세계 최악의 인권유린 국가입니다 이시간에도 북한 주민들은 김정은한테 총살당하거나 아오지탄광으로 끌려가고 있습니다 북한 여성들은 김정은의 성노예가 되고 있구요 대한한공 조현민의 갑질 화가나죠 미투운동으로 드러난 권력자들의 성폭력 정말 싫습니다 그런데 이것보다 수백배는 더심한 갑질과 성폭력을 일삼는게 북한 김정은입니다 | 0 | 3 |
Conclusions
현재의 네이버 뉴스 댓글 정렬방식은 공감수가 높은 댓글을 위주로 보여주고 있고, 기준 또한 쉽다. 조작에 들어가는 비용 대비 얻을 수 있는 효과가 큰 상황에서 조작으로 인해 이익을 볼 집단은 당연히 어뷰징을 할 수 밖에 없다. 그리고 이미 조직적인 세력이 되어버린 어뷰저들은 완벽히 차단할 수 없다. 때문에 어뷰징을 해결할 수 있는 가장 좋은 방법은 현재의 정렬 방식의 단점을 극복하면서 자연스럽게 기준이 복잡해지게 만드는 것과 사람들이 조작된 의견에 크게 흔들리지 않을 수 있도록 다양한 의견을 보여주는 것이다.
현재의 네이버 정렬 방식 중 순공감순과 공감비율순이 가지는 한계는 reddit에서 사용하고 있는 best 정렬방식으로 해결된다. 공감수에 가중치를 둔 정렬방식 외에 공감수와 비공감수가 비슷한 댓글에 가중치를 두는 방식, 비공감수에 가중치를 두는 방식을 제안하였다.
한 쪽의 의견만 듣는 것은 언제나 편향된 결과를 야기한다고 생각한다. 한 쪽이 명백히 잘못한 것처럼 보도될 때, 그 반대의 의견에도 귀를 기울일 수 있는 플랫폼이 되길 바란다.
Future works
지금까지는 댓글의 contents보다는 댓글에 부과된 공감, 비공감의 interaction 데이터로 문제점과 해결방식을 제안했다. controversial로 의견의 다양성을 추구했지만 text를 보지 않았기 때문에 의견의 다양성을 간접적으로 보장하기엔 불안정할 수 있다.
쇼핑 리뷰에서 가격, 내구성, 디자인 등 다양한 측면을 보여주듯이 정치적 의견도 기사에서 언급된 중요한 단어들에 대한 사람들의 반응을 보는 방식도 생각해보면 좋을 것 같다.
Appendix A: Wilson score
사실 본문에서 기술한 내용은 일반적인 Normal approximation interval이다.
\[ p = \hat{p} \pm z\sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \]
여기서 \(\)은 Bernoulli process의 성공확률을 의미한다.
Wilson score는 confidence interval을 \(\)가 아닌 \(p\)로 추정한 score interval의 최소값이다.
\[ p = \hat{p} \pm z\sqrt{\frac{p(1-p)}{n}} \]
\(p\)에 대해 정리하여 \(p\)에 대한 2차방정식을 만든다.
\[ (1 + \frac{z^2}{n}) p^2 - (2\hat{p} + \frac{z^2}{n})p + \hat{p}^2 = 0 \]
근의 공식을 사용해 \(p\)를 구한다.
\[ p = \frac{2n\hat{p} + z^2 \pm z\sqrt{z^2 + 4n\hat{p}(1-\hat{p})}}{2(n+z^2)} \]
Wilson score는 \(p\)의 lower bound이므로 - 에 대해 정리하면 다음과 같다.
\[ w^- = max(0, \frac{2n\hat{p} + z^2 - z\sqrt{z^2 + 4n\hat{p}(1-\hat{p})}}{2(n+z^2)}) = \text{wilson score} \]
95%의 신뢰도로 고정하는 경우 z에 1.96을 대입할 수 있다. 그리고 이
경우 본문의 python 함수에서 구현한 best가 된다.
References
- 1.2017년 11월 30일부터 호감순에서 순공감순으로 변경되면서 다시 2016년 이전의 호감순처럼 호감도를 “공감-비공감”으로 계산하게 되었다. ↩︎
- 2.홍준표 “나경원, 아들 이중국적 여부 밝혀라…1억 피부과 연상”, 네이버 뉴스 ↩︎
- 3.재판에 넘겨진 조국 부인 정경심 교수…검찰 '소환 임박', 네이버 뉴스 ↩︎
- 4.대학교수 이어 의사 4400명도 “조국 퇴진, 조국 딸 퇴교” 시국선언문 서명, 네이버 뉴스 ↩︎
- 5.https://redditblog.com/2009/10/15/reddits-new-comment-sorting-system ↩︎
- 6.http://www.evanmiller.org/how-not-to-sort-by-average-rating.html ↩︎
- 7.https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval#Wilson_score_interval ↩︎
- 8.https://blog.yelp.com/2011/02/the-most-romantic-city-on-yelp-is ↩︎
- 9.MB '정치보복' 반발에 문무일 총장 “법적 절차대로 하겠다”, 네이버 뉴스 ↩︎
- 10.https://www.reddit.com/r/NoStupidQuestions/comments/3xmlh8/what_does_something_being_labeled_controversial/?sort=confidence ↩︎
- 11.아베 “한미군사훈련 예정대로”…文대통령 “내정문제 거론 곤란”(종합), 네이버 뉴스 ↩︎