
한국어 악성댓글 탐지를 위한 댓글 코퍼스 구축기
약 4-5개월동안 사이드로 진행했던 혐오 댓글 프로젝트[1]가 성공적으로 마무리되었다. 같은 문제의식을 가진 사람들과 시작해서 각자 하고싶었던 내용을 조율하고, 혐오 댓글이 무엇인가에 대해 깊게 고민해보는 과정들이 쉽진 않았지만 의미있는 활동이라는 생각이 들었다. 또한, 사이드로 진행된 프로젝트임에도 불구하고 원동력이 사라지지 않고 꾸준히 일이 진행되었던 것은 모두 구성원들의 상호보완적인 역량 덕분이 아니었을까 싶다.
사실 이 글을 쓰게 된 계기는 논문에는 쓰지 못했던 데이터에 대한 이야기를 하고 싶어서였다. 주어진 4장에 많은 내용을 담으려다보니 정작 작업하면서 고려했던 세부사항이나 어려웠던 점, 지나고나니 아쉬웠던 부분들에 대해 적진 못했기 때문이다. 아마 데이터셋을 활용하려고 생각하는 사람들에게도 좋은 팁이 되지 않을까?
어노테이션
왜 편견과
혐오인가?
어노테이션
가이드라인에도 나와있듯이 우리는 크게 편견과 혐오라는 두 가지
aspect에 대해서 label을 수집했다. 처음에는
성에 관련된 편견 및 혐오와
그 외의 편견 및 혐오로 나누었는데, 이보다는
편견과 혐오로 구분하는 것이 낫다는 판단을
했다.
가이드라인 작성을 위해 댓글을 직접 태깅하다 보니 편견만 존재하는
댓글과 혐오만 존재하는 댓글이 존재했다. 항상 혐오가 편견으로부터
시작되지는 않았고, 편견이 있음을 부끄러워하지 않고 세상의 진리인 것처럼
이야기하는 댓글이 보였다. 혐오가 편견으로 시작된 경우는, 무리하게 개인의
특성을 집단의 특성으로 확장해서 그 집단에 대한 혐오를 개인에게 표출할
때였다. 그래서 이 둘의 관계를 데이터로 파악할 수 있도록, 또 편견과
혐오를 구분지어 생각할 수 있도록 편견에 관련된 label과
혐오에 관련된 label을 구분짓기로 했다.
언어학에 관심있는 사람들이라면 label을 바탕으로 댓글을 분석하는 것으로도 재밌는 연구가 될 것 같다.
표현의 자유와 혐오의 경계
이 둘을 구분짓는 좋은 threshold를 결정하는 것은 무슨 목적으로 활용하냐에 달려있다. 우리의 목적은 혐오 댓글의 피해자가 줄어들기를 바라는 것이었으므로 익명인의 표현의 자유보다는 기사의 대상이 되는 사람의 기분을 좀 더 신경쓰기로 했다. 그래서 태깅을 할 때에 당사자의 입장에서 생각하도록 가이드했다.
어노테이션이 어려웠던 댓글
예전에 데뷔작에서 수영복입고 수중씬 기억난다 진짜 섹씨했는데
연예인이라는 직업이 가지는 특수성 때문에 판단하기 어려웠던 경우이다. 특히 여자연예인에 대해서는 외모에 대해 품평하는 댓글이 많았는데, 스스로가 연예인이었던 적이 없으니 감정이입을 해서 이를 모욕이라고 봐야할지도 모르겠고, 만약 의도적으로 외모를 부각해서 유명세를 얻은 경우라면 모욕이라고 보기가 더 어렵다고 생각했다. 결국 각자의 판단에 맡겨서 majority voting을 했지만 정말 어려웠던 케이스였다.
신천지?
"일반적으로 비난받을만한 행위로 인한 혐오는 어떻게 판단해야할까?" 를
고민하게 만든 댓글이었다. 신천지 교도로 인해 코로나가 빠르게 퍼졌던 사건
이후로 "신천지"는 부정적인 이미지로 굳어져 버렸는데, 이 맥락을 고려해서
위의 댓글을 혐오라고 태깅하면 "신천지"라는 가치 중립적인
단어가 혐오로 태깅되기에 굉장히 고민이 많았습니다.
살빠진 마닷같애
위와 비슷한 케이스로 이 댓글 또한 판단하기 무척이나 어려웠다 ㅠㅠ
offensive로 판단하자니 마닷은 뭐가 되냐는...
Other biases 라는
label
현재는 bias label이 gender bias,
other biases, none 의 세가지로 구성되어 있다.
이렇게 할 수 밖에 없었던 가장 큰 이유는 예산 문제였다 ㅠㅠ 돈이 많았다면
gender 외에도 정치, 지역, 인종 등에 대한 편견도 label을 수집할 수
있었을텐데 하는 아쉬움이... 인당 150만원 이상은 부담하고 싶지 않아서,
그리고 연예 도메인은 성 편견이 가장 많은 비중을 차지하고 있어서 이런
결정을 하게 되었다.
그러다보니 others 라는 label 은 온갖 종류의 편견이 모두
모아져 있다. 아마도 모델이 곧장 others 를 예측하는 것은 쉽지 않을
것이라고 생각한다. 이 task는, 논문에 적혀있듯이, 2-step
classification 문제를 푸는 방식이 낫지 않을까라고 생각한다. 먼저
gender / no-gender 를 예측하고, 그 이후에
bias 유 / 무 를 예측하면 gender,
others, none 을 좀 더 쉽게 예측할 수 있을
것이라고 생각한다.
어노테이션 작업 시 context 미제공
댓글에 포함된 편견 및 혐오를 더욱 정확하게 판단하기 위해서는 댓글이 작성된 뉴스 기사에 대한 정보가 필요하다. 하지만 현실적인 이유들로 포기했었다.
"작업자가 기사를 읽어야 하는 번거로움을 감수할까?"
"태깅 플랫폼에서 이 기능을 제공해줄까?"
"뉴스 기사의 내용에 대한 저작권은 우리에게 없기 때문에 공개 데이터셋에 포함할 수 없고, 그럴거라면 태깅을 컨텍스트 없이 하는게 좋지 않을까?"
등의 질문들에 대해 명쾌한 답변을 내리지 못했고, 결국 댓글의 내용만 보고 판단하는 방식을 가져갔다. 지나고나니 아쉬움이 남는 건 어쩔 수 없는듯하다.
Testset 구성
현재 testset은 함께 작업했던 저와 조원익, 이준범이 직접 작업한 라벨이 달려있다. 우리의 의도와 부합하는, 가장 어노테이션이 잘 되었다고 보장할 수 있는 데이터셋이라고 볼 수 있다. 하지만 지나고나니 "시간 순으로 train, validation, testset을 구성했다면 어땠을까?" 하는 아쉬움이 남았다.
댓글에는 많은 사회적 배경지식이 녹아져있다. 특히 인물의 이름이 가지고 있는 정보가 있는데, 우리가 수집한 기간에는 승리와 정준영 등의 연예인이 얽혀있던 단톡방 사건이 포함되어 있었다. 그래서 "승리"가 포함된 댓글은 부정적인 맥락 속에서 판단되었다.
예를 들어 "승리가 뭘 잘못했다고 난리들인지...그냥 승리 부럽고 베알꼴린 애들이 화난거로밖에 안보임ㅎ" 라는 댓글에서 "승리"를 제거하면 성편견이 없는 것으로 태깅되었겠지만, "승리"가 포함되었기 때문에 성편견이 존재하는 것으로 태깅된다.
Generalization을 잘 하는 모델이 진짜 잘하는 모델이라고 했을 때, 학습 데이터에 "승리"가 없어도 위의 댓글에 달린 라벨을 잘 예측할 수 있는 모델을 판별할 수 있게 testset을 구성했다면 더 좋았을 것 같다.
KoBERT tokenization
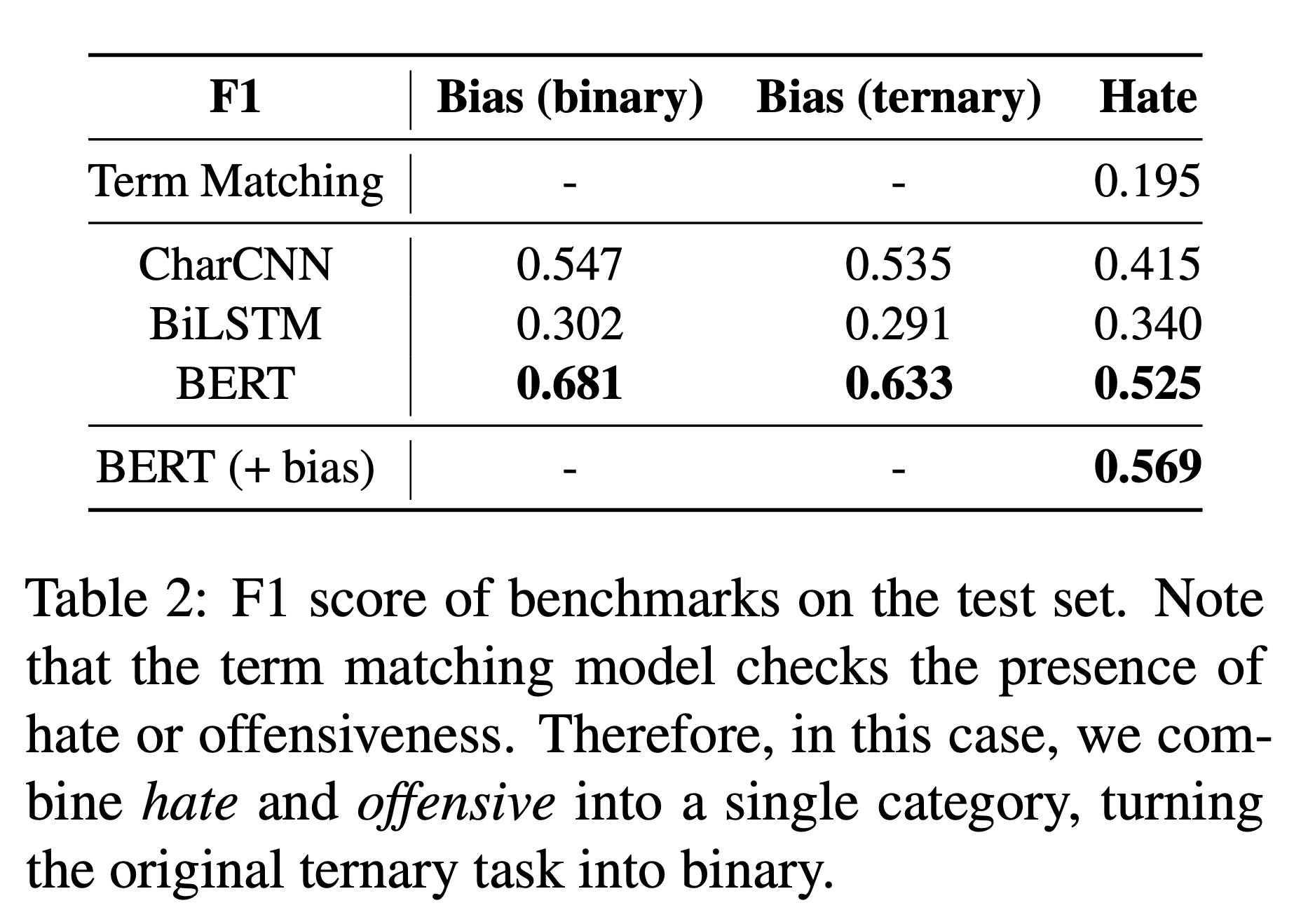
baseline으로 CharCNN, BiLSTM, BERT를 사용한 모델의 결과를 논문[2]에 첨부했다. 여러 task 모두 BERT가 가장 좋은 성능을 보였다.
댓글은 맞춤법을 지키는 문장과는 거리가 멀고, 줄임말, 신조어, 연예인명, 그리고 그 외의 고유명사 등이 많이 등장한다. 그래서 BERT tokenization 결과를 보면 한 글자 씩 분리되는 경우가 빈번했다.
페지해라 가세연. 페지가 답이다 아님말고식 증거도없이 유재석 언급하노 |
god 박준형이 이 기사를 싫어합니다. |
koBERT 학습 데이터에 자주 등장했던 연예인 이름은 원본 그대로 보존되는 반면, 그렇지 못한 연예인은 이름이 쪼개진다.
조개갖고 개ㅈㄹ하는 태콩이나 개촐싹대는조샌징들이나 ㅈㄴ웃김ㅋㅋㅋ |
ㅅㅂ 더럽게 메갈어로 제목뽑는거 봐라 |
"ㅈㄴ", "ㅈㄹ", "ㅅㅂ" 같은 단어가 tokenization에서는 쪼개지지 않는다.
어려웠던 작업이었고, 완벽했다고는 할 수 없지만 좋은 시작점이 될 수 있는 프로젝트였다고는 생각한다. 이번에 해결할 수 없었던 여러 한계점들을 극복하는 다른 좋은 결과들이 많이 나올 수 있길 :)
이제 진짜 끝!